

Note: To follow best practices guide, you must have the Persisted Streams add-on in Striim Cloud or Striim Platform.
Introduction
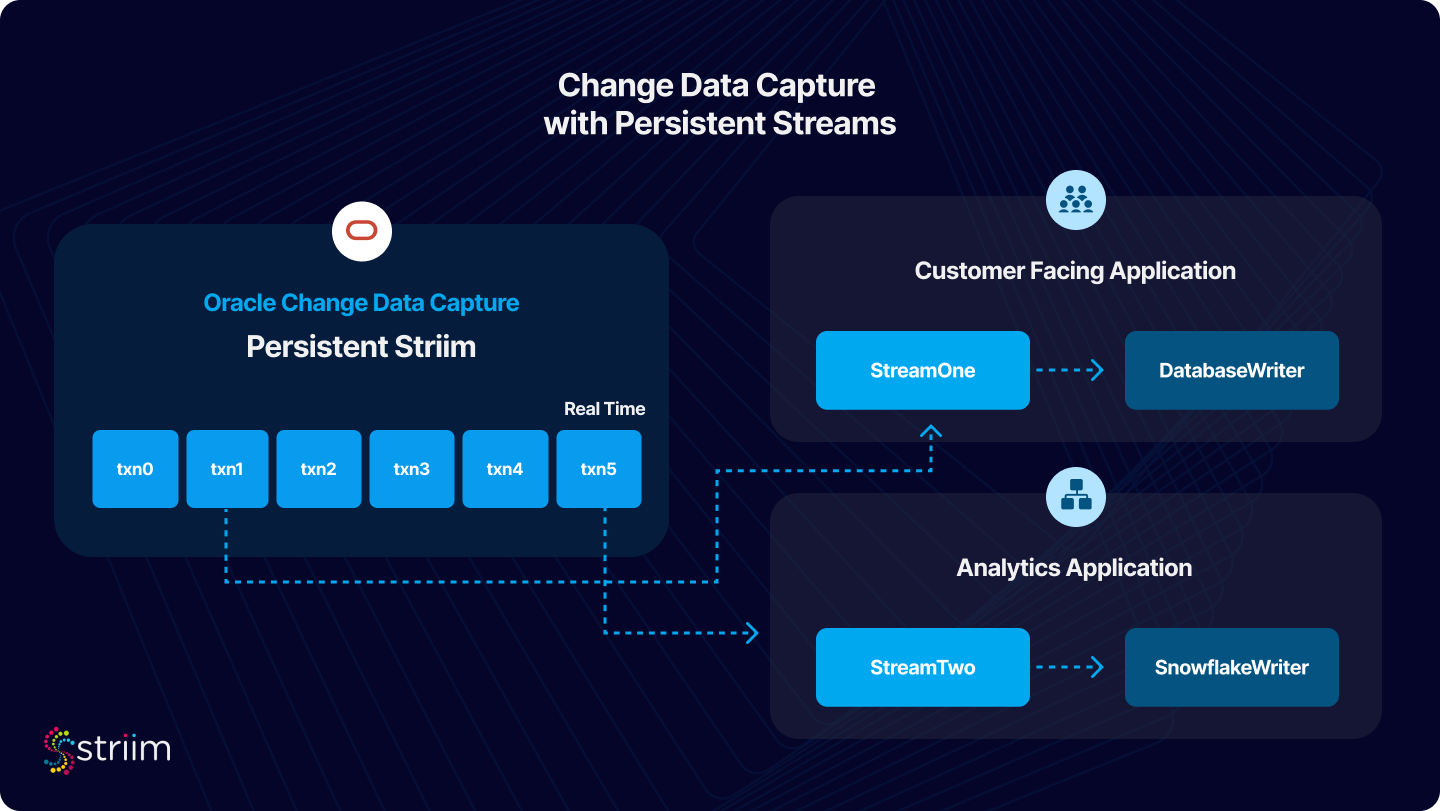
Change Data Capture (CDC) is a critical methodology, particularly in scenarios demanding real-time data integration and analytics. CDC is a technique designed to efficiently capture and track changes made in a source database, thereby enabling real-time data synchronization and streamlining the process of updating data warehouses, data lakes, or other systems.
Change Data Capture to Multiple Subscribers
It is common for organizations to stream transactional data from a database to multiple consumers – whether it be different lines of the business or separate technical infrastructure (databases, data warehouses, and messaging systems like Kafka).
However, a common anti-pattern in CDC implementation is creating a separate read client for each subscriber. This might seem intuitive but is actually inefficient due to competing I/O and additional overhead created on the source database.
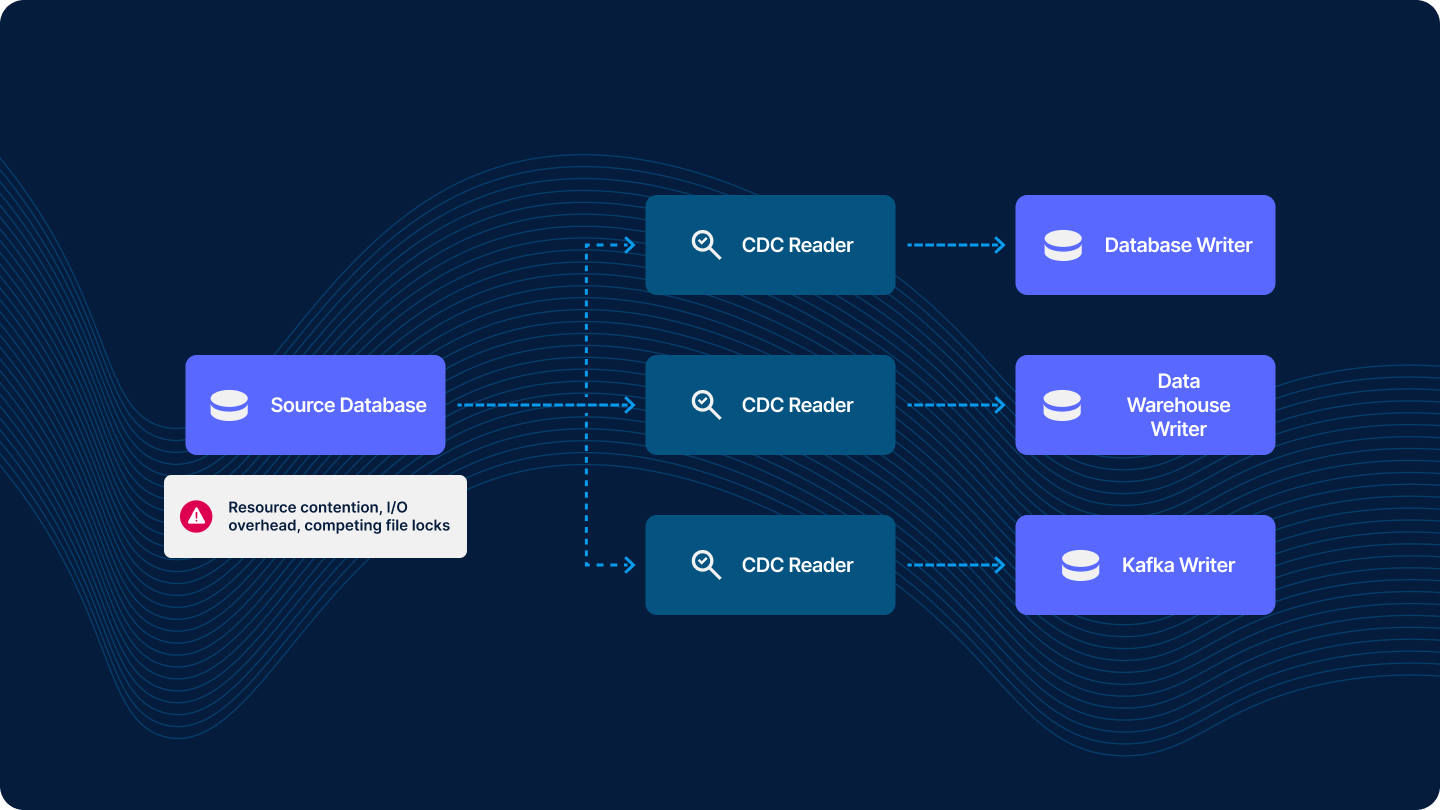
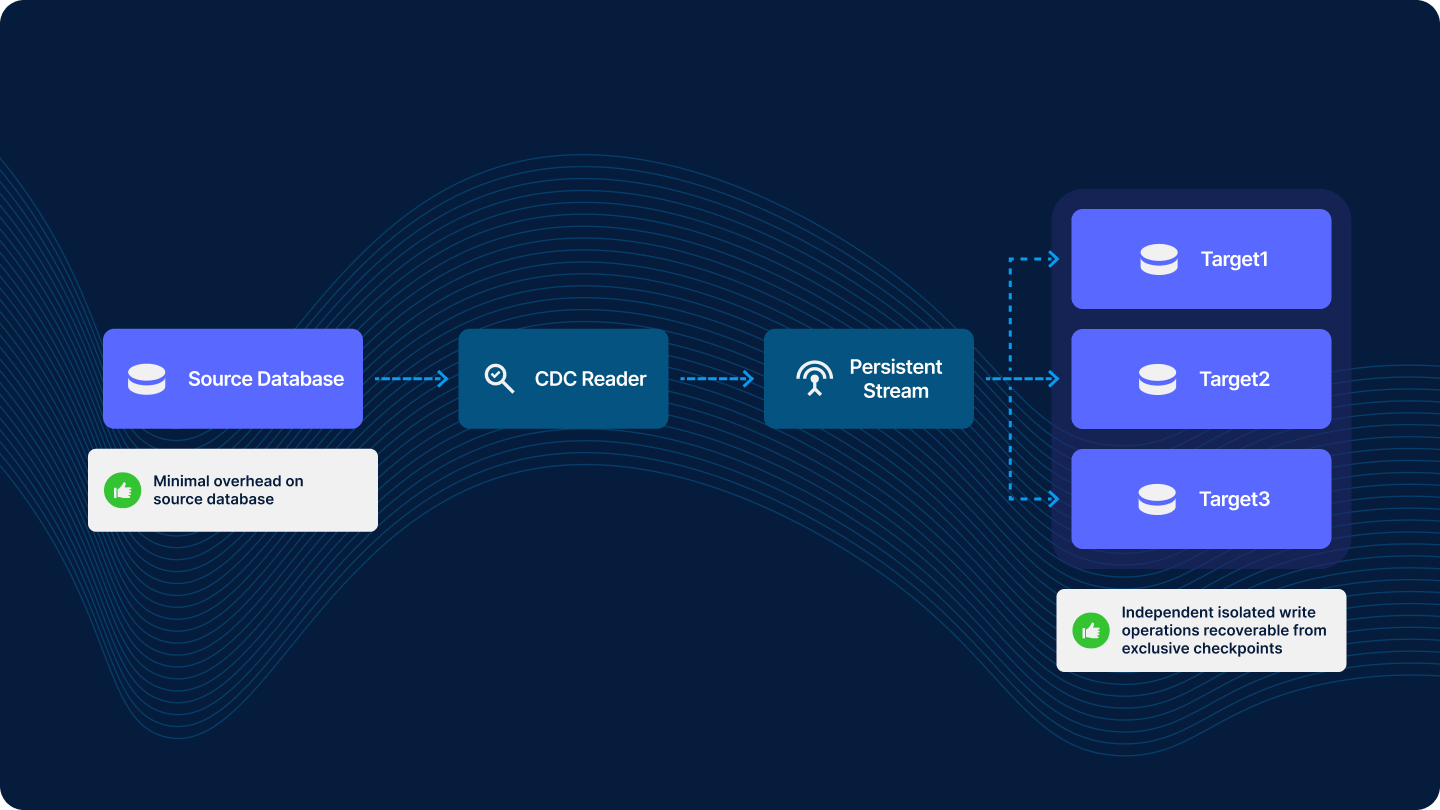
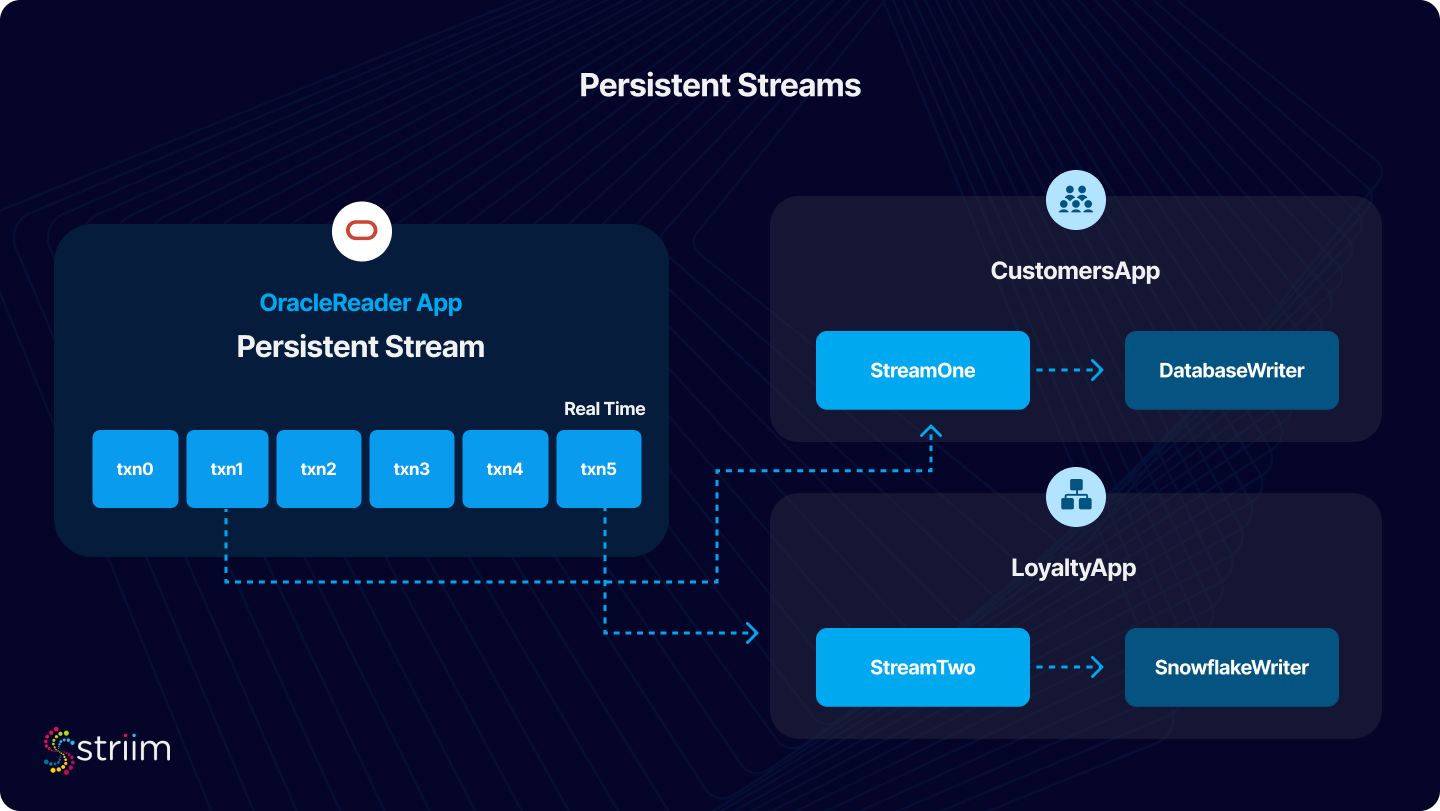
The more efficient approach is to have a single read client that pipes out to a stream, which is then ingested by multiple writers. Striim addresses this challenge through its implementation of Persistent Streams, which manage data delivery and recovery across application boundaries.
Concepts and definitions for this article
- Striim App: Deployable Directed Acyclic Graph (DAG) of data processing components in Striim.
- Stream: Time-ordered log of events transferring data between processing components.
- Source (e.g., OracleReader): Captures real-time data changes from an external system and emits a stream of events
- Targets: Writes a stream of events to various external systems.
- Router: Directs data from an input stream to two or more stream components based on rules
- Continuous Query (CQ): Processes data streams using a rich Streaming SQL language
- Persistent Streams: Transfers data between components in a durable, replayable manner.
- Transaction log:A chronological record of all transactions and the database changes made by each transaction, used for ensuring data integrity and recovery purposes.
Enhanced Role of Persistent Streams in Striim for Data Recovery and Application Boundary Management
Persistent Streams in Striim play a critical role in data recovery and managing data flows across application boundaries. They address a common challenge in data streaming applications: ensuring data consistency and integrity, especially during recovery processes and when data crosses boundaries between different applications.
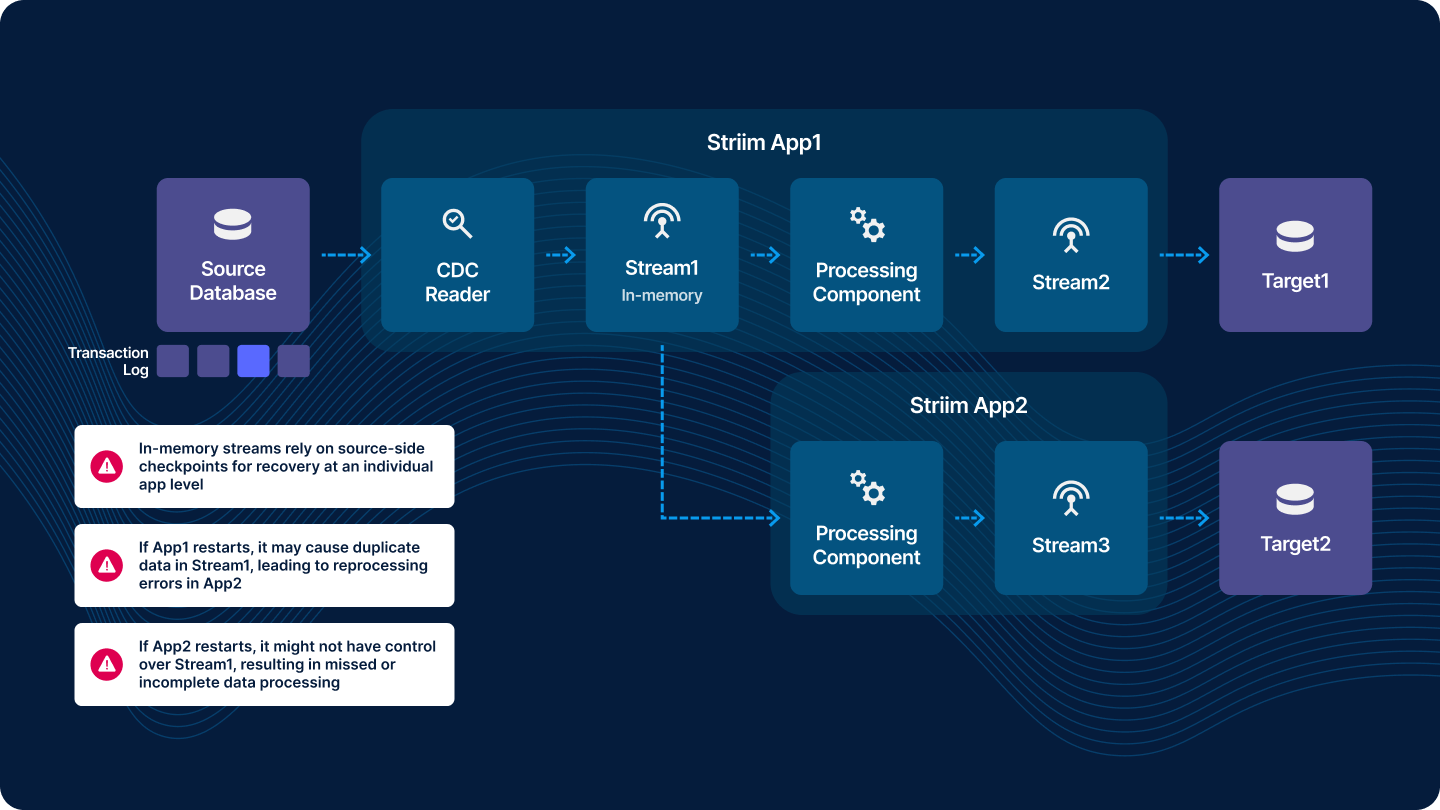
In-Memory Streams vs. Persistent Streams
In traditional streaming setups without Persistent Streams, data recovery and consistency across application boundaries can be problematic. Consider the following scenario with two Striim applications (App1 and App2):
A database transaction log is a chronological record of all transactions and the database changes made by each transaction, used for ensuring data integrity and recovery purposes.
Persistent Streams for Recovery and Application Boundary Negotiation
To mitigate these challenges, Persistent Streams offer a more sophisticated approach:
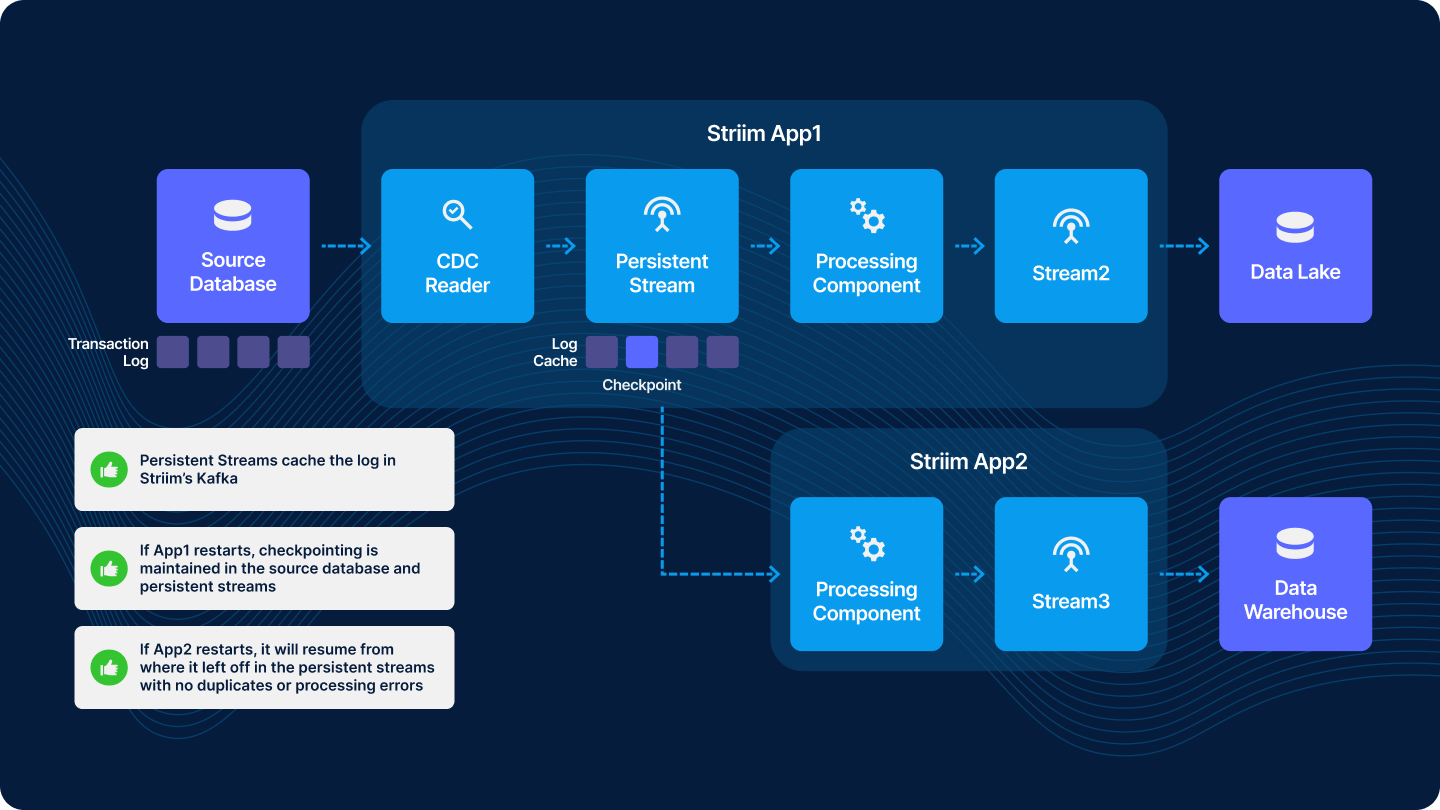
In this setup, Persistent Streams allow for a more controlled and error-free data flow, especially during restarts or recovery processes. Here’s how they work:
- Rewind and Reprocessing: Persistent Streams enable the rewinding of data flows, allowing components to reprocess a portion of the stream backlog. This ensures that data flows are reset properly during recovery.
- Independent Checkpoints: Each subscribing application (example App2) maintains its own checkpoint on the Persistent Stream. This means that each app interacts with the stream independently, enhancing data consistency and integrity.
- Private Stream Management: Applications can stop, start, or reposition their interaction with the Persistent Stream without affecting other applications. This autonomy is crucial for maintaining uninterrupted data processing across different applications.
- Controlled Data Flow: Each application reads from the Persistent Stream at its own pace, reaching the current data head and then waiting for new data as needed. This controlled flow prevents data loss or duplication that can occur with traditional streams.
- Flexibility for Upstream Applications: The upstream application (like App1 in our example) can write data into the Persistent Stream at any time, without impacting the downstream applications. This flexibility is vital for dynamic data environments.
Designing pipelines to read once, stream anywhere
Application Boundary Negotiation with Persistent Streams
Persistent Streams in Striim play a pivotal role in managing data flows across application boundaries, ensuring Exactly Once Processing. They provide a robust mechanism for recovery by rewinding data flows and allowing reprocessing of the stream backlog. For example, in a scenario where two applications share a stream:
In this setup, Persistent Streams allow each application to maintain its own checkpoint and process data independently, avoiding issues like data duplication or missed data that can occur when traditional streams are used across application boundaries. This approach ensures that each downstream application can operate independently, maintaining data integrity and consistency.
Kafka-backed Streams in Striim
Striim offers integration with Kafka, either fully managed by Striim or with an external Kafka cluster, to manage Persistent Streams. This add-on is available in both Striim Cloud and Striim Platform.
See enabling Kafka Streams in Striim Platform (self-hosted).
To create a Persistent Stream, follow the steps in our documentation.
To set up Persistent Streams in Striim Cloud, simply check the ‘Persistent Streams’ box when launching your service. You can then use the ‘admin.CloudKafkaProperties’ to automatically persist your streams to the Kafka cluster fully managed by Striim.
Striim Router for Load Distribution
Striim provides several methods to distribute and route change data capture streams to multiple subscribers. To route data based on simple rules (e.g. table name, operation type), we generally recommend using a Striim Router component.
A Router component to channel events to related streams based on specific conditions. Each DatabaseWriter is connected to a stream defined by the Router.
CREATE STREAM CustomerTableGroupStream OF Global.WAEvent;
CREATE STREAM DepartmentTableGroupStream OF Global.WAEvent;
CREATE OR REPLACE ROUTER event_router INPUT FROM OracleCDCOut AS src
CASE
WHEN meta(src, "TableName").toString().equals("QATEST.DEPARTMENTS") OR
meta(src, "TableName").toString().equals("QATEST.EMPLOYEES") OR
meta(src, "TableName").toString().equals("QATEST.TASKS") THEN
ROUTE TO DepartmentTableGroupStream,
WHEN meta(src, "TableName").toString().equals("QATEST.CUSTOMERS") OR
meta(src, "TableName").toString().equals("QATEST.ORDERS") THEN
ROUTE TO CustomerTableGroupStream;Copy
The event router is assigned the task of routing incoming data from the OracleCDCOut source to various streams, determined by predefined conditions. This ensures efficient data segregation and processing based on the incoming event’s table name.
Flow Representation:
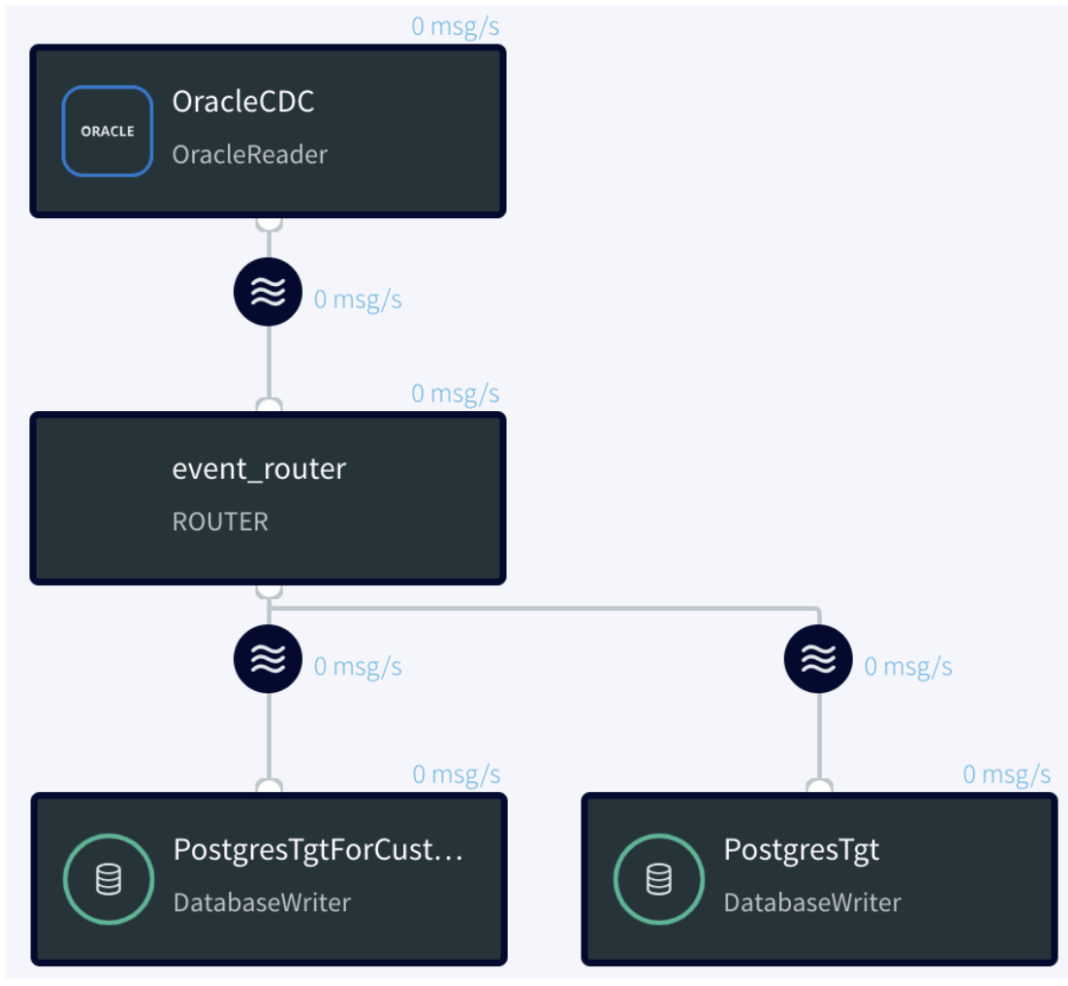
The Reader reads from the “interested tables” and writes to a single stream. The Router then uses table name-based case statements to direct the events to multiple writers.
Designing the Striim Apps with Resource Isolation
For a read once, Write Anywhere CDC pattern, you will create Striim apps that handle reading from a source database, moving data with Persistent Streams, and routing data to various consumers.
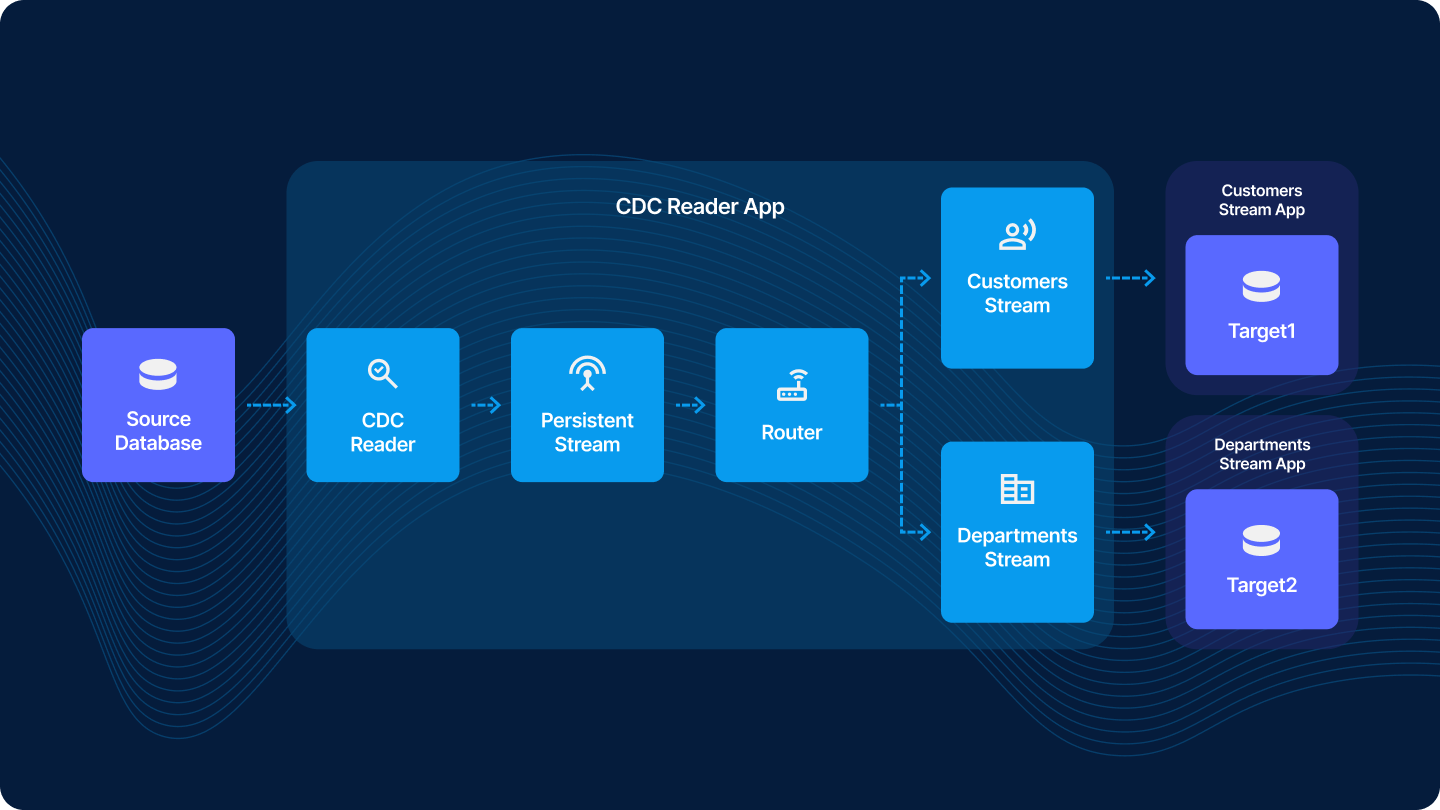
Be sure to enable Recovery on all applications created in this process. Review Striim docs on steps to enable recovery.
CDC Reader App: An app with a CDC reader that connects to the source Database that outputs to the Persistent Stream
For each database that you will perform CDC from, create an application to source data and route to downstream consumers.
Sample TQL:
CREATE OR REPLACE APPLICATION CDC_App USE EXCEPTIONSTORE TTL : '7d', RECOVERY 10 seconds ;
CREATE SOURCE OracleCDC USING Global.PostgreSQLReader (
Username: 'cdcuser',
ConnectionURL:<your connection URL>,
Password: <your password>,
ReplicationSlotName: 'striiim_slot',
Password_encrypted: 'true',
Tables: <your tables>
connectionRetryPolicy: 'retryInterval=30, maxRetries=3',
FilterTransactionBoundaries: true )
OUTPUT TO CDCStream PERSIST USING admin.CloudKafkaProperties;
END APPLICATION CDC_App;Copy
This app will then contain a CQ or a Router to route the ‘CDCStream’ to multiple streams. For simplicity and minimizing event data, we recommend using the Router. Create a Router to route data from the persistent CDCStream to an in-memory stream for each downstream app that you will create.
The entire app will have the below components..
Sample TQL:
CREATE OR REPLACE APPLICATION CDC_App USE EXCEPTIONSTORE TTL : '7d', RECOVERY 10 seconds ;
CREATE SOURCE OracleCDC USING Global.OracleReader (
Username: 'cdcuser',
ConnectionURL:<your connection URL>,
Password: <your password>,
ReplicationSlotName: 'striiim_slot',
Password_encrypted: 'true',
Tables: <your tables>
connectionRetryPolicy: 'retryInterval=30, maxRetries=3',
FilterTransactionBoundaries: true )
OUTPUT TO CDCStream PERSIST USING admin.CloudKafkaProperties;
CREATE STREAM CustomerTableGroupStream OF Global.WAEvent PERSIST USING admin.CloudKafkaProperties ;
CREATE STREAM DepartmentTableGroupStream OF Global.WAEvent admin.CloudKafkaProperties;
CREATE OR REPLACE ROUTER event_router INPUT FROM CDCStream AS src
CASE
WHEN meta(src, "TableName").toString().equals("QATEST.DEPARTMENTS") OR
meta(src, "TableName").toString().equals("QATEST.EMPLOYEES") OR
meta(src, "TableName").toString().equals("QATEST.TASKS") THEN
ROUTE TO DepartmentTableGroupStream,
WHEN meta(src, "TableName").toString().equals("QATEST.CUSTOMERS") OR
meta(src, "TableName").toString().equals("QATEST.ORDERS") THEN
ROUTE TO CustomerTableGroupStream;
END APPLICATION CDC_App;Copy
Create apps for each downstream subscriber
Now you will create an app that reads data from the Database CDC Stream App’s streams.
CREATE OR REPLACE APPLICATION CustomerTableGroup_App USE EXCEPTIONSTORE TTL : '7d', RECOVERY 10 seconds ;
CREATE TARGET WriteCustomerTable USING DatabaseWriter (
connectionurl: 'jdbc:mysql://192.168.1.75:3306/mydb',
Username:'striim',
Password:'******',
Tables: <your tables>
) INPUT FROM CDC_App.CustomerTableGroupStream;
END APPLICATION CustomerTableGroup_App;Copy
Here we will create the second application that reads data from Database CDC Stream App’s streams:
CREATE OR REPLACE APPLICATION Departments_App USE EXCEPTIONSTORE TTL : '7d', RECOVERY 10 seconds ;
CREATE TARGET WriteDepartment USING DatabaseWriter (
connectionurl: 'jdbc:mysql://192.168.1.75:3306/mydb',
Username:'striim',
Password:'******',
Tables: <your tables>
) INPUT FROM CDC_App.DepartmentTableGroupStream;
END APPLICATION DepartmentsApp;Copy
You can repeat this pattern n-number of times for n-number of consumers. It’s also worth noting you can have multiple consumers (Striim apps with a Target component) on the same physical target data platform – e.g. multiple Striim Targets for a single Snowflake instance. For instance, you may split out the target for a few critical tables that require dedicated compute and runtime resources to integrate.
Once you’ve designed these Striim applications, they will be independently recoverable and maintain their own upstream checkpointing with Striim’s best-in-class transaction watermarking capabilities.
Designing the Striim Apps with Resource Sharing
To consolidate runtime and share resources between consumers, you can also bundle both Targets in the same Striim app. This means if one consumer goes down, it will halt the pipeline for all consumers. If your workloads are uniform and you have no operational advantages from decoupling, you can easily keep all the components in the same app.
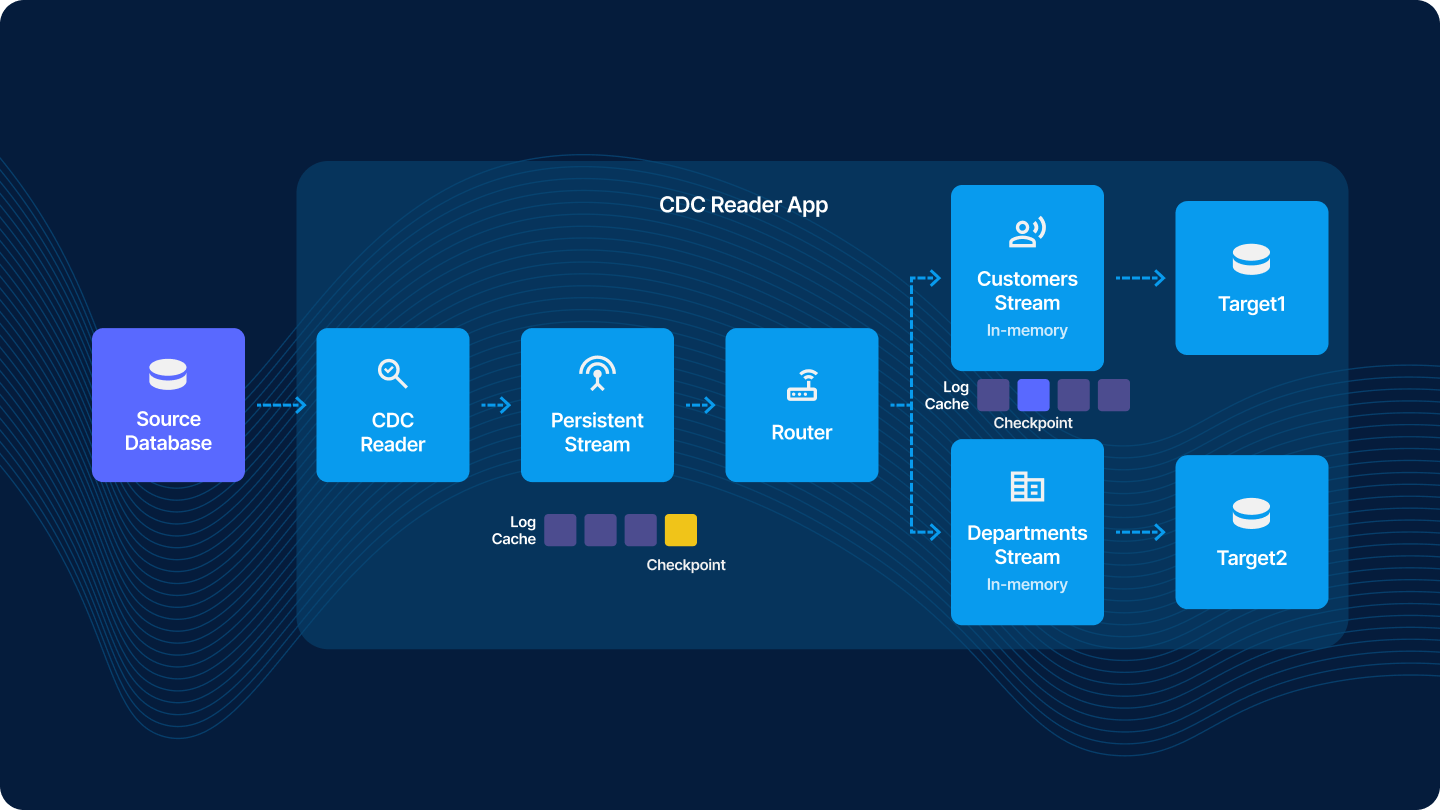
You would simply create all components within one application.
CREATE OR REPLACE APPLICATION CDC_App USE EXCEPTIONSTORE TTL : '7d', RECOVERY 10 seconds ;
CREATE SOURCE OracleCDC USING Global.PostgreSQLReader (
Username: 'cdcuser',
ConnectionURL:<your connection URL>,
Password: <your password>,
ReplicationSlotName: 'striiim_slot',
Password_encrypted: 'true',
Tables: <your tables>
connectionRetryPolicy: 'retryInterval=30, maxRetries=3',
FilterTransactionBoundaries: true )
OUTPUT TO CDCStream PERSIST USING admin.CloudKafkaProperties;
CREATE STREAM CustomerTableGroupStream OF Global.WAEvent admin.CloudKafkaProperties;
CREATE STREAM DepartmentTableGroupStream OF Global.WAEvent admin.CloudKafkaProperties;
CREATE OR REPLACE ROUTER event_router INPUT FROM CDCStream AS src
CASE
WHEN meta(src, "TableName").toString().equals("QATEST.DEPARTMENTS") OR
meta(src, "TableName").toString().equals("QATEST.EMPLOYEES") OR
meta(src, "TableName").toString().equals("QATEST.TASKS") THEN
ROUTE TO DepartmentTableGroupStream,
WHEN meta(src, "TableName").toString().equals("QATEST.CUSTOMERS") OR
meta(src, "TableName").toString().equals("QATEST.ORDERS") THEN
ROUTE TO CustomerTableGroupStream;
CREATE TARGET WriteCustomer USING DatabaseWriter (
connectionurl: 'jdbc:mysql://192.168.1.75:3306/mydb',
Username:'striim',
Password:'******',
Tables: <your tables>
) INPUT FROM CDC_App.CustomerTableGroupStream;
CREATE TARGET WriteDepartment USING DatabaseWriter (
connectionurl: 'jdbc:mysql://192.168.1.75:3306/mydb',
Username:'striim',
Password:'******',
Tables: <your tables>
) INPUT FROM CDC_App.DepartmentTableGroupStream;
END APPLICATION CDC_App;Copy
Grouping Tables
Striim provides exceptional flexibility processing multi-variate workloads by allowing you to group different tables into their own apps and targets. As demonstrated above, you can either group tables into their own target in the same app (in the resource sharing example), or provide fine-grained resource isolation by grouping tables into their own target into their own respective Striim app. An added benefit is you can still use a single source to group tables.
Here are some criteria for group tables
- Data freshness SLAs
- Group tables into a Striim target based on data freshness SLA. You can configure and tune the Striim target’s batchpolicy/uploadpolicy based on the SLA
- Data volumes
- Group tables with similar transaction volumes into their own apps and targets. This will allow you to optimize the performance of delivering data to business consumers.
- Tables with relationships – such as Foreign Keys – should also be grouped together
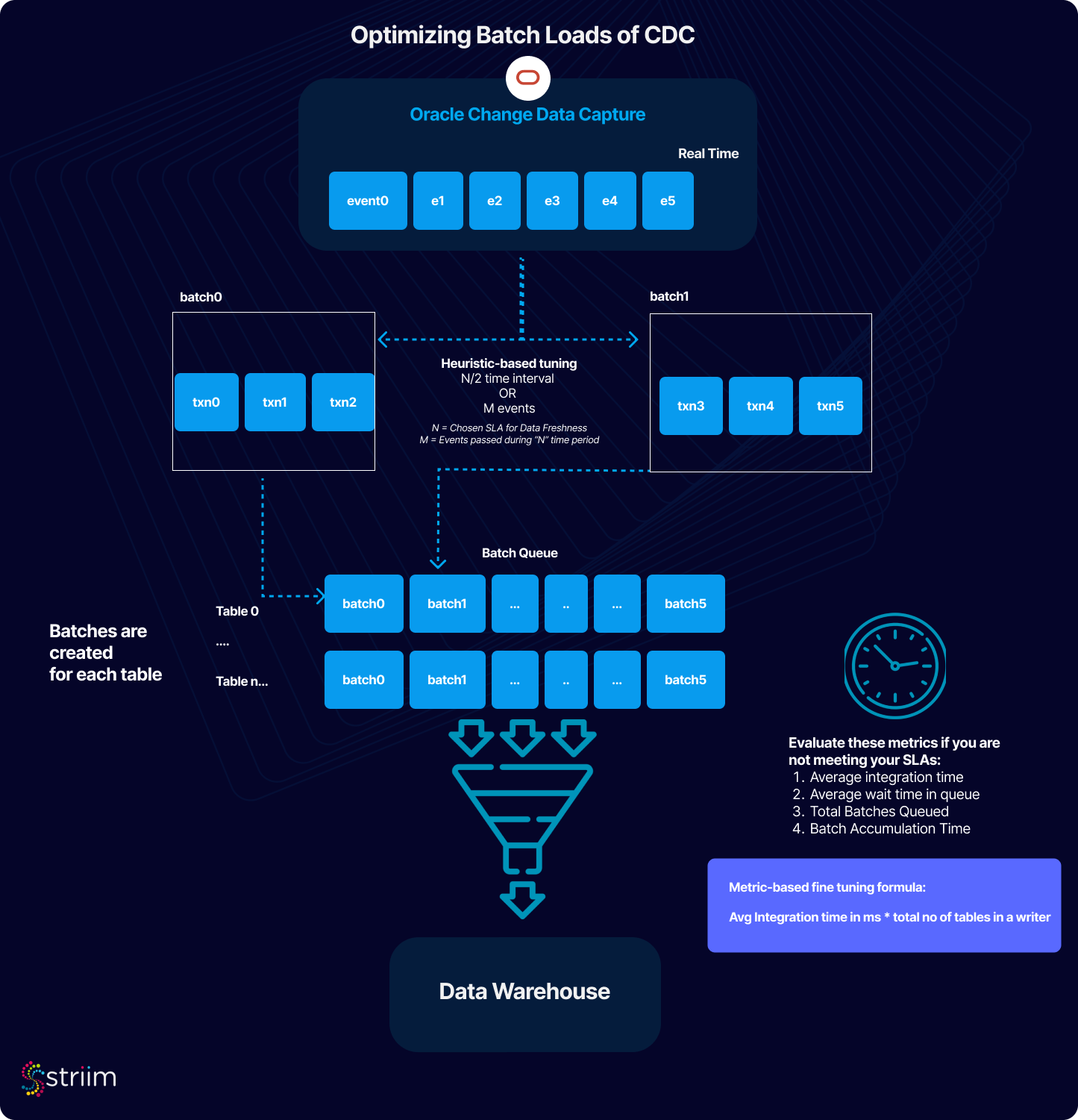
After you group your tables into their respective targets based on the above criteria, you can apply heuristic-based tuning to get maximum performance, cost reduction, and service uptime.
Tuning Pipelines for Performance
We recommend heuristic-based tuning of Striim applications to meet the business and technical performance requirements of your data pipelines. You can set your Striim Target adapters batch policy accordingly:
- Choose a Data Freshness SLA for the concerned set of tables you are integrating to the target – defined as N.
Measure the number of DMLs created by your source database during the timeframe of ‘N’ – defined as M.
Here are some on tuning approaches with the available metrics:
- Avg Integration Time in ms – Indicates the average time for batches to successfully write to the target based on current runtime performance
- Avg Waiting time in Queue in ms – Indicates the average time a batch is queued for integration to the target.
- Total Batches Queued – Indicates the number of batches queued for integration to the target.
- Batch Accumulation Time – The time it takes for a batch hit the expiration threshold
- If Batch Accumulation Time is longer than your batch policy, it may be a sign of an overloaded writer. Conversely, it may indicate a table has very low volume and can be grouped in its own target.
When writing to analytics targets such as Google BigQuery, Snowflake, Microsoft Fabric and Databricks, Striim’s target writers have a property called ‘BatchPolicy’ (or UploadPolicy) which defines the interval in which batches should be uploaded to the Target systems. The Batchpolicy is a hybrid of time and number of events; whichever occurs first. Batches are created on a per table basis, regardless of how many tables are defined in your Target’s ‘tables’ property. Using the above variables, set your BatchPolicy as
Time interval: N/2.
Events: M
This means we will create batches to upload to your target at either a time of N/2 OR for every M events. These analytical systems are efficiently designed for large data ingress in periodic chunks, Striim recommends setting N/2 and M to values that maximize the write performance of the target system to meet business SLAs and technical objectives.
There are several factors that hinder or reduce write performance of the target systems. Often these factors fall into these categories, when evaluating the best values for N and M. They are:
- Tables Model and workload design such as indexes, partitions, clustering, and efficient row update seeks.
- Quotas, shared compute resources allocations, global API and load severs utilization.
- Network configurations, CSP region location, and competing application utilization.
Slower than expected upload performance often becomes evident when batches from various tables are enqueued at a faster rate than dequeued. As each Target writer in Striim executes a job this queue is reduced. As the enqueuing of jobs proceeds sequentially upon batch policy expiration, if progress in the jobs processing occurs the queue will grow and will no longer sustain workload demands. Reduced write performance leads to delays (lag) in data availability and reliability errors such as out-of-memory (OOM) conditions or API service contention, particularly during streaming uploads.
Additionally enqueue of batches can also occur from additional causes other than target performance. The causes at a high level are:
- Rapid Batch Policy Expiration: This is caused by overly aggressive Adapter policy settings. Such as setting M = 1000 when A workload of 1M rows is processed by a series of DML updates on the source system. The batch policy would expire and enqueue target loads faster than the time required for upload and merge operations, leading to an increasing backlog. To mitigate this, adjust the EventCount and Interval values in the BatchPolicy. A common cause of rapid expiration is setting a low EventCount.
- High Source Input Rate: An elevated rate of incoming data can intensify the upload contention. A diverse group of high frequency tables may require Implementing multiple target writers. Each additional writer increases the number of job processing compute threads and effectively increases the available load processing queues servicing the target system. While beneficial for compute parallelism this may increase quota usage and / or resource utilization of the target data system.
- High Average Wait Time in Queue: Reducing the number of batches by increasing batch size and extending time intervals can also be effective in alleviating these bottlenecks and enhancing overall system performance.
To monitor and address bottlenecked uploads causing latency, processing delays, and OOM errors, focus on the following monitoring metrics:
- Set Alerts for SourceIdle and TargetIdle customized to be describe your data freshness SLA of n.
- Run ‘LEE <source> <target>’ command
- If LEE is within n, then you may be meeting your freshness SLA. However there’s still a possibility that your last transaction read watermark is greater than n. In which case validate with the below steps
- Run ‘Mon <source>’ command
- If the current time minus ‘Reader Last Timestamp’ is less than n, then you may be meeting your freshness SLAs. However if that number is greater than n, you can start triaging the rest of the pipeline with the below steps.
- Run ‘Mon <target>’ command
- The following metrics are critical for diagnosis of issues. The time it takes to load data is heavily influenced by the below metrics:
- Avg Integration Time in ms – Indicates the average time for batches to successfully write to the target based on current runtime performance
- Avg Waiting time in Queue in ms – Indicates the average time a batch is queued for integration to the target.
- Total Batches Queued – Indicates the number of batches queued for integration to the target.
- Batch Accumulation Time – The time it takes for a batch hit the expiration threshold
-
- Update your BatchPolicy’s time interval value. This value should be equal to Avg Integration time in ms * total no of tables in a writer
- If there are a significant number of batches queuing up (using Total Batches Queued) , and ‘Average integration time in ms’ is greater than ‘n’, then increase the Batchpolicy interval value. Test again with incremental values until you are consistently meeting your SLAs.
- If your target is Snowflake – keep in mind the file upload size should be between 100-250 mb at most before copy performance begins to degrade
- An alternative to increasing the batch sizes is splitting the tables into another target and using the same heuristic. Creating a Target dedicated to high volume tables adds dedicated compute to a set of tables. However if you hit CPU bottlenecks at a Striim service level, you may need to increase your service size
Note: If a Striim Target is a Data Warehouse writer utilizing ‘optimized merge’ setting and a source is generating many Primary Key (PK) updates, each update will be batched separately and write performance will decline.
FAQ
Q: What if I have tables with different data delivery SLAs and priorities? E.g. my ‘Orders table’ has a 1 minute SLA and my ‘Store Locations’ table has a 1 hour SLA.
A: You can use a Router to split the CDC Reader’s Persistent Stream into multiple persistent streams, then create an Striim app with its own target for each set of tables with varying SLAs.
Q: What if I don’t have the Persistent Streams add-on in Striim? Can I follow these steps?
A: You can still minimize overhead on your source database by running one reader per database, but you will need to design a solution to handle recovery across apps if you have multiple consumers or prepare to do full re-syncs in the event of a transient failure.
Conclusion
Optimizing CDC in Striim involves leveraging key components like Persistent Streams, Routers, and Continuous Queries. The ‘Read Once, Write Anywhere’ pattern, facilitated by Persistent Streams, ensures efficient data distribution, integrity, and recovery across application boundaries. This approach is essential for effective real-time data integration and analytics in modern business environments.